Last Updated on January 15, 2021

I have data to suggest that Shopify hasn’t been serving a robots.txt file consistently (if at all) since at least January 4th (and looks to have just been fixed today, 5pm GMT January 15th).
The image above shows how 690,000 urls went from blocked to crawlable on the 4th Jan, and I’ve verified this issue today across multiple sites robots.txt files, with all of them displaying HTML code for a 404 page within the file itself instead of the usual robots.txt rules.
There are also numerous examples in GSC of the last recorded robots.txt file crawled being on the 4th Jan.
Definitely one to watch out for in case it happens again/isn’t fully fixed yet – put other tags in place as a safeguard.
One example of how this could lead to major indexing issues:
A store that hasn’t configured their filter pages to noindex, now suddenly has filter combinations indexable (previously blocked by the “+” in the robots.txt file), which could exponentially increase the number of indexable pages.
Here’s an image showing what has been shown to Google in the robots.txt file (the 404 page html):
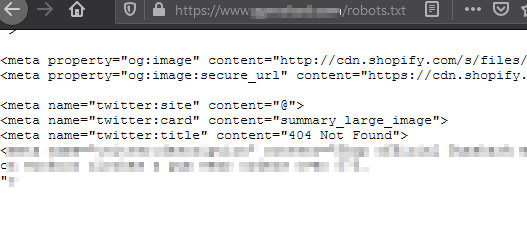
I’d be interested to see if anyone else sees these large drops in blocked pages in GSC (I’ve checked about 10 so far and nearly all have similar drops).
Related SEO Guides:


This Post Has 0 Comments